There is a significant demand for Apache Spark because it is the most actively developed open-source engine for data processing on computer clusters. This engine is now a standard data processing tool for developers and data scientists who want to work with big data. Spark supports a variety of common languages (Python, Java, Scala, and R), includes libraries for a variety of tasks, from SQL to streaming and machine learning, and can run on a laptop to a cluster of thousands of servers. This makes it simple to start and increase in size to massive data processing or a wide range of applications.
Apache Spark has grown in popularity thanks to the involvement of more than 500 coders from across the world’s biggest companies and the 225,000+ members of the Apache Spark user base. Alibaba, Tencent, and Baidu are just a few of the famous examples of e-commerce firms that use Apache Spark to run their businesses at large.
The Spark architecture is explained in this article via a spark architecture diagram. It is a one-stop shop for information on Spark architecture.
Confused about your next job?
What is Spark?
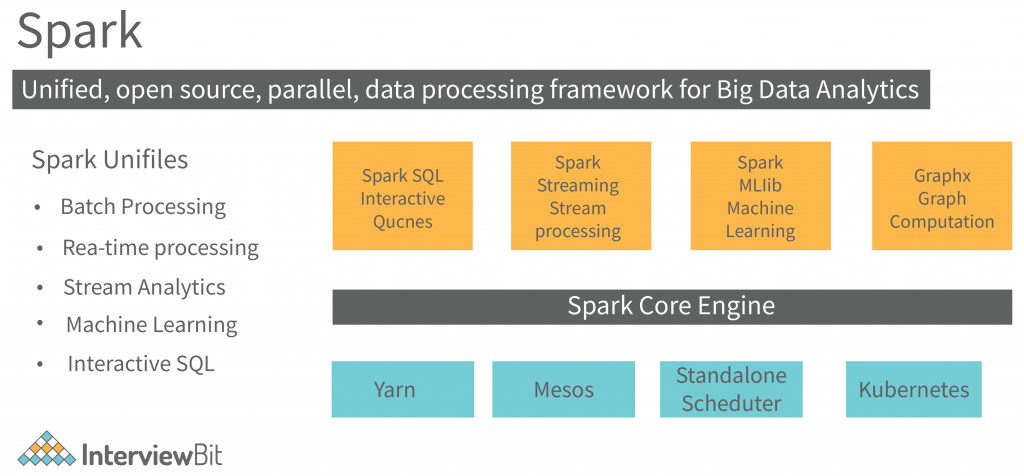
Spark Architecture, an open-source, framework-based component that processes a large amount of unstructured, semi-structured, and structured data for analytics, is utilised in Apache Spark. Apart from Hadoop and map-reduce architectures for big data processing, Apache Spark’s architecture is regarded as an alternative. The RDD and DAG, Spark’s data storage and processing framework, are utilised to store and process data, respectively. Spark architecture consists of four components, including the spark driver, executors, cluster administrators, and worker nodes. It uses the Dataset and data frames as the fundamental data storage mechanism to optimise the Spark process and big data computation.
Apache Spark Features
Apache Spark, a popular cluster computing framework, was created in order to accelerate data processing applications. Spark, which enables applications to run faster by utilising in-memory cluster computing, is a popular open source framework. A cluster is a collection of nodes that communicate with each other and share data. Because of implicit data parallelism and fault tolerance, Spark may be applied to a wide range of sequential and interactive processing demands.
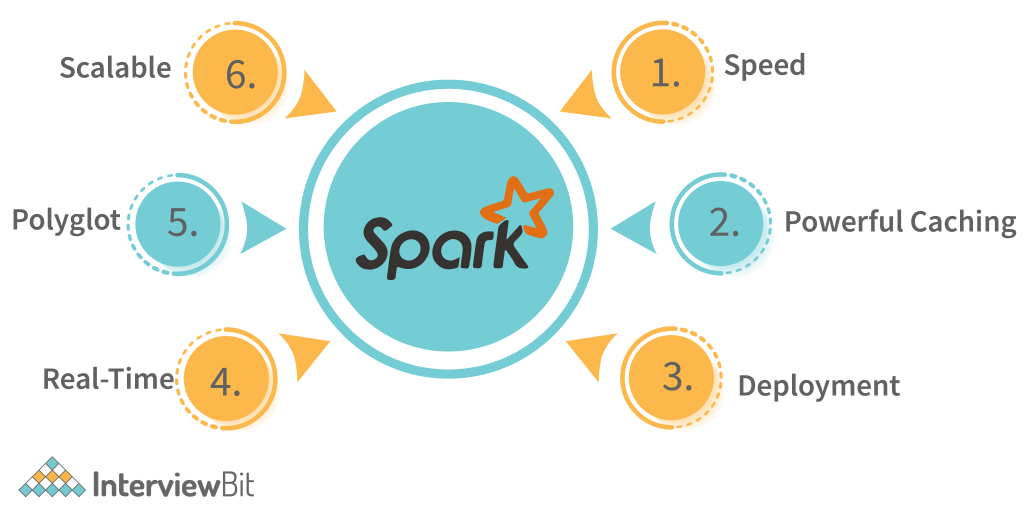
- Speed: Spark performs up to 100 times faster than MapReduce for processing large amounts of data. It is also able to divide the data into chunks in a controlled way.
- Powerful Caching: Powerful caching and disk persistence capabilities are offered by a simple programming layer.
- Deployment: Mesos, Hadoop via YARN, or Spark’s own cluster manager can all be used to deploy it.
- Real-Time: Because of its in-memory processing, it offers real-time computation and low latency.
- Polyglot: In addition to Java, Scala, Python, and R, Spark also supports all four of these languages. You can write Spark code in any one of these languages. Spark also provides a command-line interface in Scala and Python.
Two Main Abstractions of Apache Spark
The Apache Spark architecture consists of two main abstraction layers:
Resilient Distributed Datasets (RDD):
It is a key tool for data computation. It enables you to recheck data in the event of a failure, and it acts as an interface for immutable data. It helps in recomputing data in case of failures, and it is a data structure. There are two methods for modifying RDDs: transformations and actions.
Directed Acyclic Graph (DAG):
The driver converts the program into a DAG for each job. The Apache Spark Eco-system includes various components such as the API core, Spark SQL, Streaming and real-time processing, MLIB, and Graph X. A sequence of connection between nodes is referred to as a driver. As a result, you can read volumes of data using the Spark shell. You can also use the Spark context -cancel, run a job, task (work), and job (computation) to stop a job.
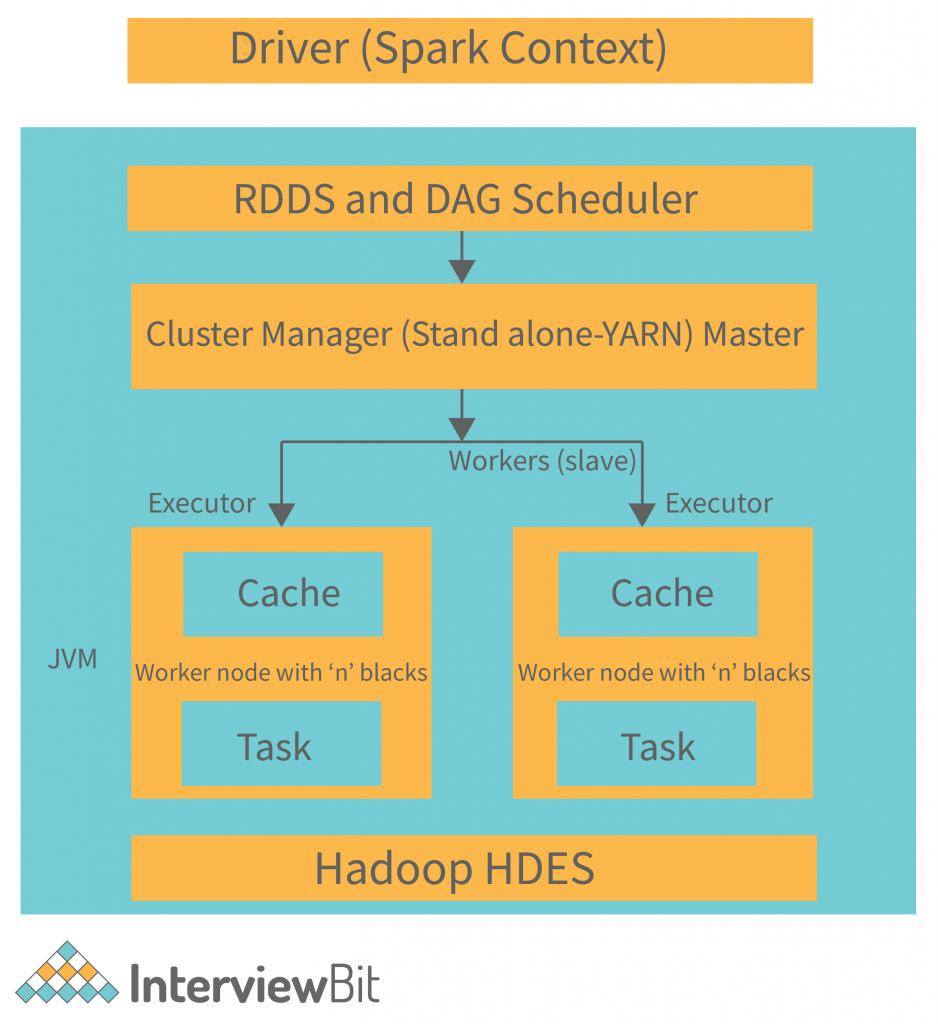
Spark Architecture
The Apache Spark base architecture diagram is provided in the following figure:
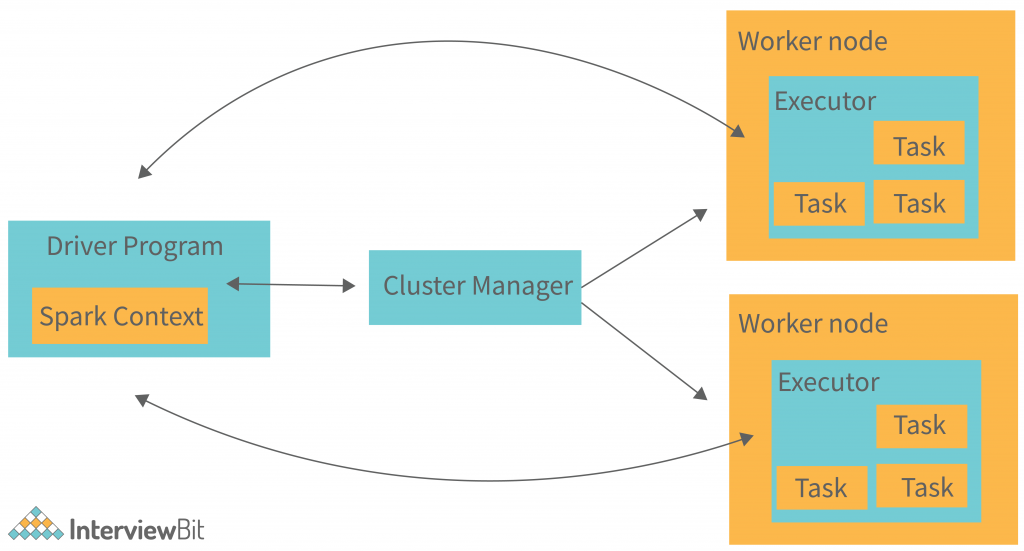
When the Driver Program in the Apache Spark architecture executes, it calls the real program of an application and creates a SparkContext. SparkContext contains all of the basic functions. The Spark Driver includes several other components, including a DAG Scheduler, Task Scheduler, Backend Scheduler, and Block Manager, all of which are responsible for translating user-written code into jobs that are actually executed on the cluster.
The Cluster Manager manages the execution of various jobs in the cluster. Spark Driver works in conjunction with the Cluster Manager to control the execution of various other jobs. The cluster Manager does the task of allocating resources for the job. Once the job has been broken down into smaller jobs, which are then distributed to worker nodes, SparkDriver will control the execution.
Many worker nodes can be used to process an RDD created in the SparkContext, and the results can also be cached.
The Spark Context receives task information from the Cluster Manager and enqueues it on worker nodes.
The executor is in charge of carrying out these duties. The lifespan of executors is the same as that of the Spark Application. We can increase the number of workers if we want to improve the performance of the system. In this way, we can divide jobs into more coherent parts.
Spark Architecture Applications
A high-level view of the architecture of the Apache Spark application is as follows:
The Spark driver
The master node (process) in a driver process coordinates workers and oversees the tasks. Spark is split into jobs and scheduled to be executed on executors in clusters. Spark contexts (gateways) are created by the driver to monitor the job working in a specific cluster and to connect to a Spark cluster. In the diagram, the driver programmes call the main application and create a spark context (acts as a gateway) that jointly monitors the job working in the cluster and connects to a Spark cluster. Everything is executed using the spark context.
Each Spark session has an entry in the Spark context. Spark drivers include more components to execute jobs in clusters, as well as cluster managers. Context acquires worker nodes to execute and store data as Spark clusters are connected to different types of cluster managers. When a process is executed in the cluster, the job is divided into stages with gain stages into scheduled tasks.
The Spark executors
An executor is responsible for executing a job and storing data in a cache at the outset. Executors first register with the driver programme at the beginning. These executors have a number of time slots to run the application concurrently. The executor runs the task when it has loaded data and they are removed in idle mode. The executor runs in the Java process when data is loaded and removed during the execution of the tasks. The executors are allocated dynamically and constantly added and removed during the execution of the tasks. A driver program monitors the executors during their performance. Users’ tasks are executed in the Java process.
Cluster Manager
A driver program controls the execution of jobs and stores data in a cache. At the outset, executors register with the drivers. This executor has a number of time slots to run the application concurrently. Executors read and write external data in addition to servicing client requests. A job is executed when the executor has loaded data and they have been removed in the idle state. The executor is dynamically allocated, and it is constantly added and deleted depending on the duration of its use. A driver program monitors executors as they perform users’ tasks. Code is executed in the Java process when an executor executes a user’s task.
Worker Nodes
The slave nodes function as executors, processing tasks, and returning the results back to the spark context. The master node issues tasks to the Spark context and the worker nodes execute them. They make the process simpler by boosting the worker nodes (1 to n) to handle as many jobs as possible in parallel by dividing the job up into sub-jobs on multiple machines. A Spark worker monitors worker nodes to ensure that the computation is performed simply. Each worker node handles one Spark task. In Spark, a partition is a unit of work and is assigned to one executor for each one.
The following points are worth remembering about this design:
- There are multiple executor processes for each application, which run tasks on multiple threads over the course of the whole application. This allows applications to be isolated both on the scheduling side (drivers can schedule tasks individually) and the executor side (tasks from different apps can run in different JVMs). Therefore, data must be written to an external storage system before it can be shared across different Spark applications.
- Even on a cluster manager that also supports other applications, Spark can be run if it can acquire executor processes and these communicate with each other. It’s relatively easy for Spark to operate even on a cluster manager if this can be done even with other applications (e.g. Mesos/YARN).
- The driver program must listen for and accept incoming connections from its executors throughout its lifetime (e.g., see spark.driver.port in the network config section). Workers must be able to connect to the driver program via the network.
- The driver is responsible for scheduling tasks on the cluster. It should be run on the same local network as the worker nodes, preferably on the same machine. If you want to send requests to the cluster, it’s preferable to open an RPC and have the driver submit operations from nearby rather than running the driver far away from the worker nodes.
Modes of Execution
You can choose from three different execution modes: local, shared, and dedicated. These determine where your app’s resources are physically located when you run your app. You can decide where to store resources locally, in a shared location, or in a dedicated location.
- Cluster mode
- Client mode
- Local mode
Cluster mode: Cluster mode is the most frequent way of running Spark Applications. In cluster mode, a user delivers a pre-compiled JAR, Python script, or R script to a cluster manager. Once the cluster manager receives the pre-compiled JAR, Python script, or R script, the driver process is launched on a worker node inside the cluster, in addition to the executor processes. This means that the cluster manager is in charge of all Spark application-related processes.
Client mode: In contrast to cluster mode, where the Spark driver remains on the client machine that submitted the application, the Spark driver is removed in client mode and is therefore responsible for maintaining the Spark driver process on the client machine. These machines, usually referred to as gateway machines or edge nodes, are maintained on the client machine.
Local mode: Local mode runs the entire Spark Application on a single machine, as opposed to the previous two modes, which parallelized the Spark Application through threads on that machine. As a result, the local mode uses threads instead of parallelized threads. This is a common way to experiment with Spark, try out your applications, or experiment iteratively without having to make any changes on Spark’s end.
In practice, we do not recommend using local mode for running production applications.
Cluster Manager Types
There are several cluster managers supported by the system:
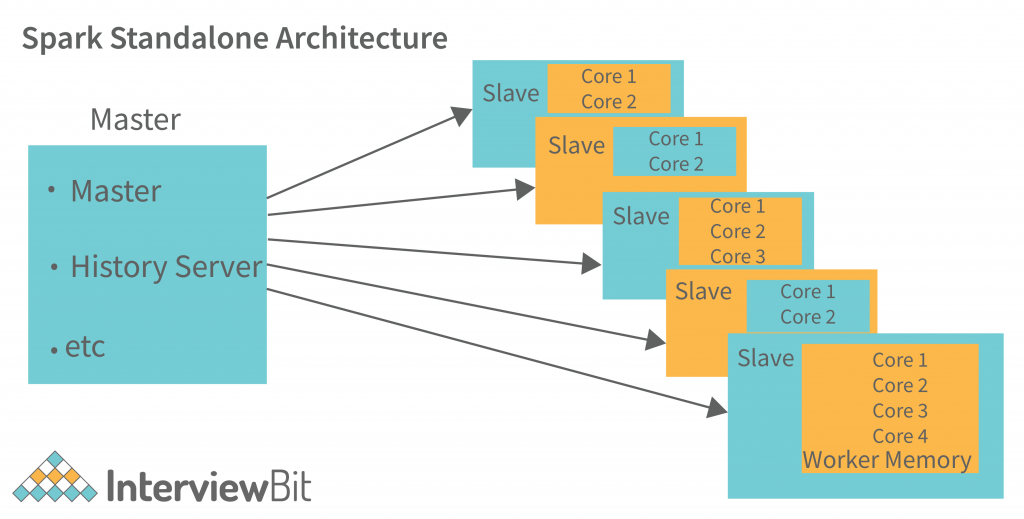
Standalone
A Spark cluster manager is included with the software package to make setting up a cluster easy. The Resource Manager and Worker are the only Spark Standalone Cluster components that are independent. There is only one executor that runs tasks on each worker node in Standalone Cluster mode. When a client establishes a connection with the Standalone Master, requests resources, and begins the execution process, a Standalone Clustered master starts the execution process.
The client here is the application master, and it wants the resources from the resource manager. We have a Web UI to view all clusters and job statistics in the Cluster Manager.
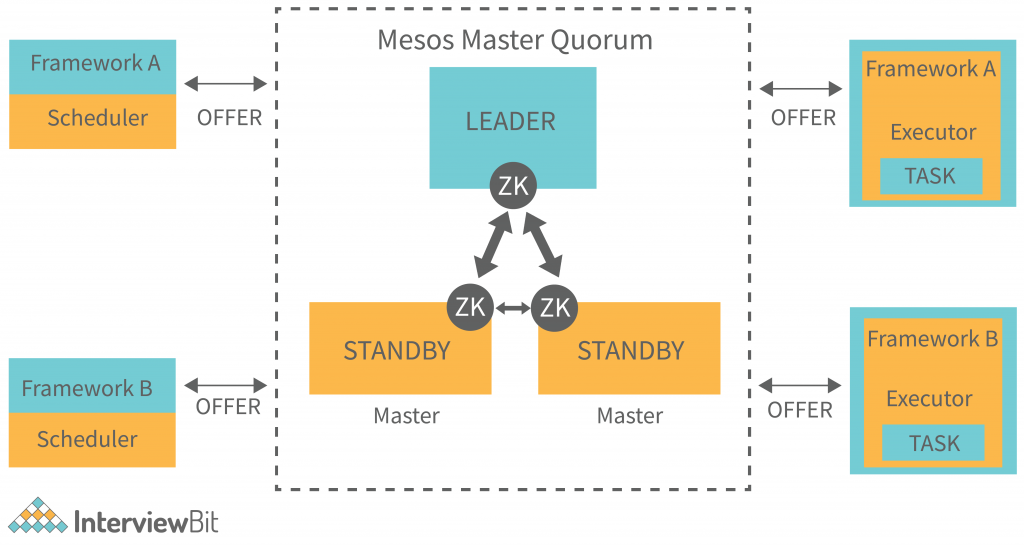
Apache Mesos
It can run Hadoop MapReduce and service apps as well as be a general cluster manager. Apache Mesos contributes to the development and management of application clusters by using dynamic resource sharing and isolation. It enables the deployment and administration of applications in large-scale cluster environments.
The Mesos framework includes three components:
- Mesos Master: A Mesos Master cluster provides fault tolerance (the capability to operate and recover from loss when a failure occurs). Because of the Mesos Master design, a cluster contains many Mesos Masters.
- Mesos Slave: A Mesos Slave is an instance that delivers resources to the cluster. When a Mesos Master assigns a task, Mesos Slave does not assign resources.
- Mesos Frameworks: Applications can request resources from the cluster so that the application can perform the tasks. Mesos Frameworks allow for this.
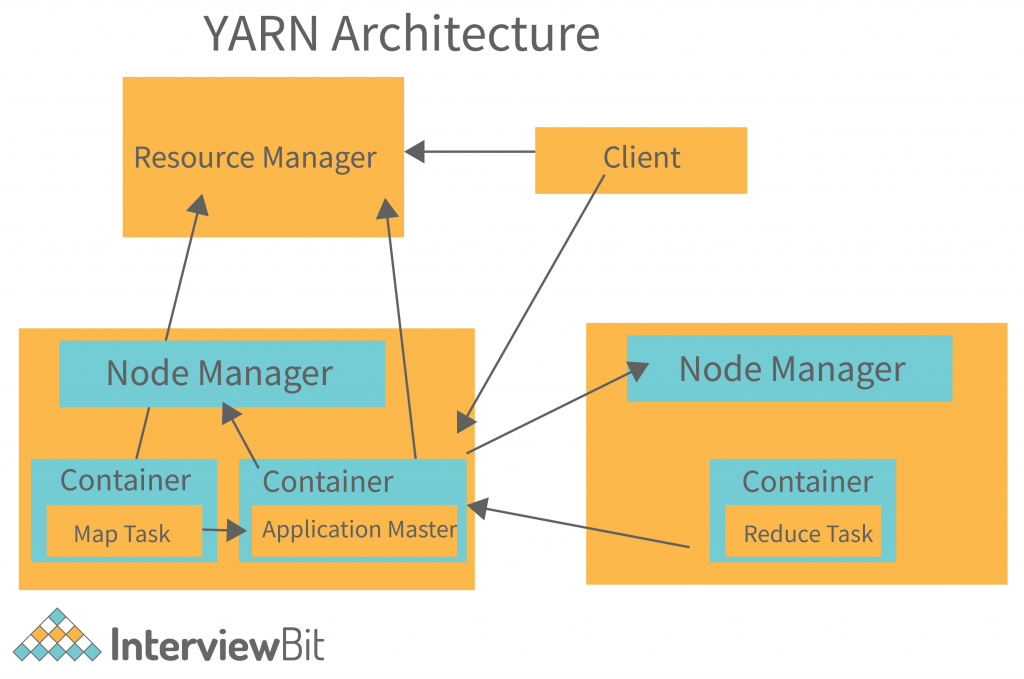
Hadoop YARN
A key feature of Hadoop 2.0 is the improved resource manager. The Hadoop ecosystem relies on YARN to handle resources. It consists of the following two components:
- Resource Manager: It controls the allocation of system resources on all applications. A Scheduler and an Application Manager are included. Applications receive resources from the Scheduler.
- Node Manager: Each job or application needs one or more containers, and the Node Manager monitors these containers and their usage. Node Manager consists of an Application Manager and a Container Manager. Each task in the MapReduce framework runs in a container. The Node Manager monitors the containers and resource usage, and this is reported to the Resource Manager.
Kubernetes
A framework for deploying, scaling, and managing containerized applications that are open source.
There is a third-party project (not supported by the Spark project) that adds support for Nomad as a cluster manager.
Conclusion
We learned about the Apache Spark Architecture in order to understand how to build big data applications efficiently. They’re accessible and consist of components, which is very beneficial for cluster computing and big data technology. Spark calculates the desired outcomes in an easy way and is popular for batch processing.
The unique elements of Spark, like datasets and data frames, help to optimise the code of the users. SQL engine and rapid execution speed are just a few of the important features of this software. Because of this software’s ability to run locally or distributed in a cluster, we’ve observed a lot of spark applications. It is thought to be a great addition to a wide variety of industries, including big data. Spark assists in tackling demanding computations.