


- What is Big Data Engineering and What does a Big Data Engineer do?
- What is the Demand for this Role?
- Big Data Engineer Salary
- Career Path of Big Data Engineer and their Growth Opportunities
- How to Become a Big Data Engineer
- Skills Required to Become Big Data Engineer
- Big Data Engineer Responsibilities
- Big Data Engineer Job Description
- When to Hire a Big Data Engineer?
- Big Data Engineer Resume
- How to Prepare for Big Data Engineer Interviews
- Conclusion
- Additional Resources
The volume, diversity, variability, and velocity of data characterize Big Data, making it important to have someone with the necessary understanding to handle it. The fact that the world will never run out of data means that Big Data Engineers all around the world will have plenty of chances to address the needs of businesses while also earning a good living. While this is understandable, let’s take a closer look at what a Big Data Engineer performs on the job.


What is Big Data Engineering and What does a Big Data Engineer do?
A Big Data Engineer is a person who is in charge of the design and development of data pipelines. Besides, they’re the ones who collect data from diverse sources and organise it into sets for analysts and data scientists to work with.
Big Data Engineers are in charge of a large number of complex datasets. The function of databases in maintaining and handling data systems and tools is becoming increasingly important as our world becomes more reliant on them.
They are also in charge of data management. This includes creating a data landscape for data scientists by utilising accessible data and tools.
They are responsible for data integration into central analysis infrastructure and determining which technologies are suitable for this. Their knowledge is not limited to the data available in the company and its storage locations; they are also responsible for determining which technologies are suitable for this.
Understanding the technological requirements is the first step in a Data Engineer’s job. They then proceed to create and build a dependable and adaptable big data infrastructure. They are in charge of data collection, storage, processing, and analysis systems. A Big Data Engineer is regarded as the data supply’s king. They make critical data easily accessible and usable across the firm and between divisions.
What is the Demand for this Role?
Every organisation in this data-driven era collects data from all possible sources, analyses it, and makes data-driven decisions.
The organization’s foundations are data pipelines, also known as ETL (Extract Transform Load) pipelines, and data warehouses. This serves as the foundation for all of the organization’s decision-making processes. The Data Engineers are in charge of designing, developing, maintaining, and optimising the entire processing system.
Various issues in storing, processing, and handling data have evolved as a result of expanding data sources and accelerated data expansion. Huge amounts of data, a high rate at which data is generated, data inconsistency, and data in a variety of formats are all major issues. This is referred to as Big Data.
“Worldwide Big Data market revenues for software and services are projected to increase from $42B in 2018 to $103B in 2027, attaining a Compound Annual Growth Rate (CAGR) of 10.48% according to Wikibon.” – Forbes
Big Data Engineer Salary
A Big Data Engineer’s average salary is roughly Rs 7,22,000 per year. Junior engineers can expect to earn roughly Rs 4,50,000 per year, while senior engineers can expect to earn around Rs 12,50,000 per year.

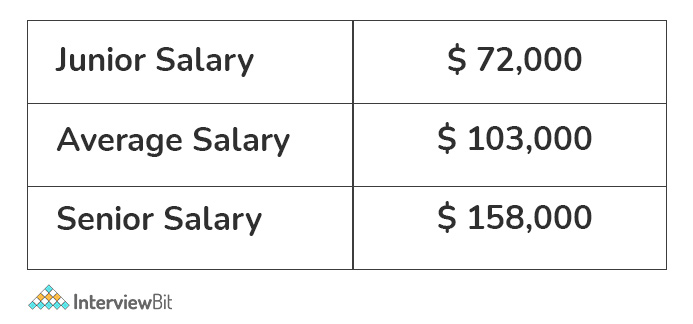
There are several other factors on which salary of Big Data Engineer depends:-
Pay by experience – entry level, mid-level and experienced level
A starting salary for a Big Data Engineer is roughly Rs 466,265 per year. The average income for an early-career Big Data Engineer or Junior Big Data Engineer (1–4 years of experience) is Rs 722,721 per year. A year’s compensation for a mid-career Big Data Engineer or Lead Big Data Engineer (5–9 years of experience) is Rs1,264,555 p.a. In India, the average compensation for a Senior Big Data Engineer is Rs. 1,681,640 per annum.

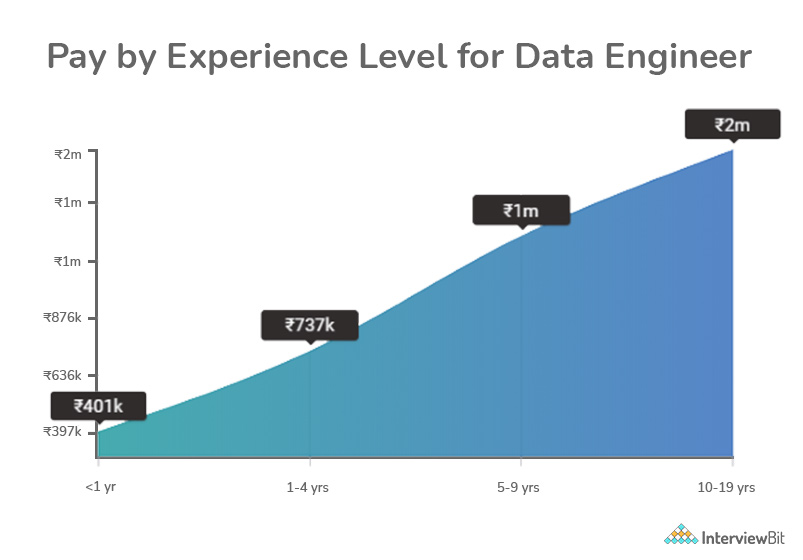

Pay by Location
The average salary of a Big Data Engineer in India is ₹820,000 per year.
- Big Data Engineer salary in Bangalore: ₹897,000 p.a.
- Big Data Engineer salary in Chennai: ₹1,171,000 p.a.
- Big Data Engineer salary in Hyderabad: ₹946,000 p.a.
- Big Data Engineer salary in Delhi: ₹820,000 p.a.
- Big Data Engineer salary in Mumbai: ₹811,000 p.a.
Pay Based on Company
The use of data has increased dramatically in recent years. More people, organizations, corporations, and other entities are using data as part of their daily routine. People used to focus more on meaningful insights and analysis, but they’ve now realized that data management is just as important. As a result, the function of a data engineer has become increasingly important in the technology industry. Data engineering is a branch of data science that focuses on practical data collecting and analysis applications. Data engineers are in charge of identifying patterns in datasets and creating algorithms to make raw data more usable to businesses.
Data Engineers are frequently paid well by reputable organizations and large participants in the Big Data market, such as Amazon, Airbnb, Spotify, Netflix, IBM, Accenture, Deloitte, and Capgemini, to mention a few.
Following is mentioned list of some top companies which hire big data engineers along with their pay scale structure:
- Tata Consultancy Services: Average salary for big data engineers- Rs 5,44,253 per year
- Cognizant: Average salary for big data engineers- Rs 9,00,000 per year
- Infosys: Average salary for big data engineers- Rs 6,00,000 per year
- Capgemini: Average salary for big data engineers- Rs 5,43,028 per year
- Deloitte: Average salary for big data engineers- Rs 15,00,000 per year
- Wipro: Average salary for big data engineers- Rs 7,17,000 per year
- JP Morgan: Average salary for big data engineers- Rs 16,00,000 per year
- Amazon: Average salary for big data engineers- Rs 17,00,000 – Rs 24,00,000 per year
- Barclays: Average salary for big data engineers- Rs 8,00,000 per year
- HCL Technologies: Average salary for big data engineers- Rs 7,00,000 – Rs 11,00,000 per year
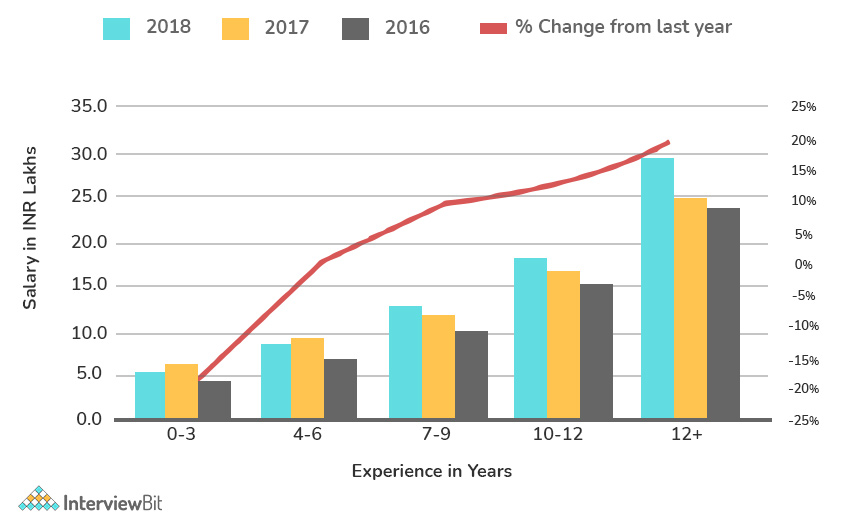
Pay based on skills – Explain the average salary based on the skills or profiles.
This is the most essential aspect of salary determination. When you read through several job descriptions, you’ll see that each one has its own set of responsibilities and qualifications. The most essential criteria in determining your income are your responsibilities and related abilities.

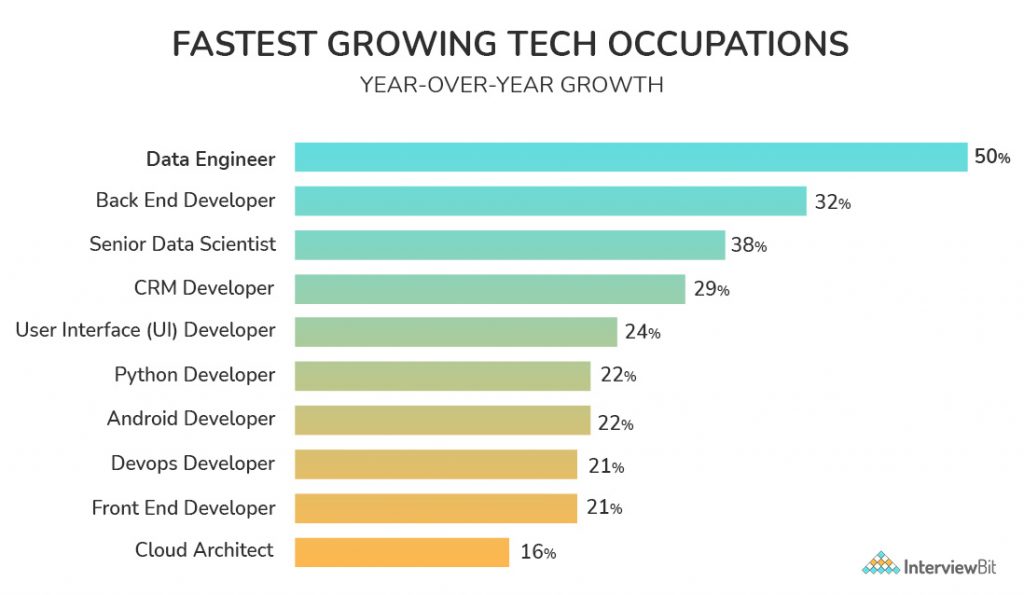


The above statistics show the increasing demand for Big Data Engineers as compared to other job roles.
Read More – Highest Paying Jobs In India
Career Path of Big Data Engineer and their Growth Opportunities

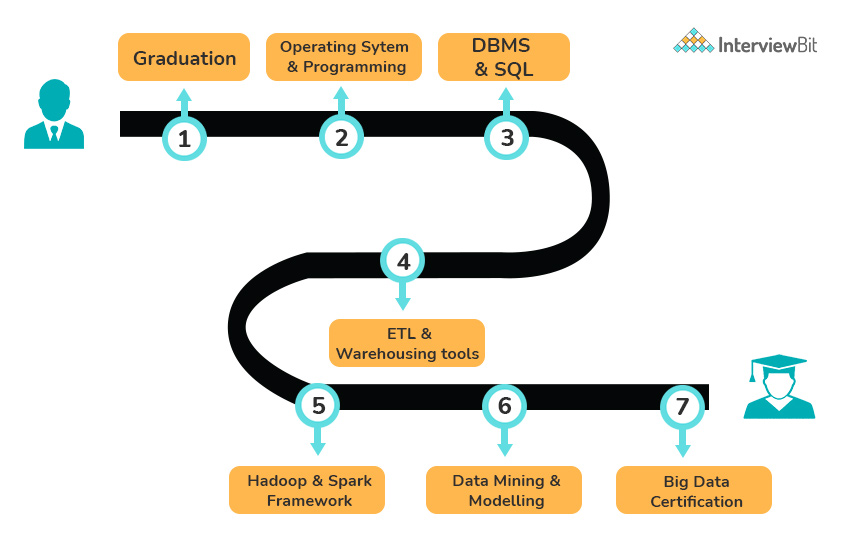
As enterprises rely on Big Data for critical decision-making, career opportunities in the field of Big Data are limitless.
A Big Data Engineer average pay in the United States is roughly $90,000 p.a, with salaries ranging from $66,000 to $130,000 p.a. The average pay in India is roughly Rs.7,00,000 p.a, with salaries ranging from Rs.400,000 to Rs.14,00,000 p.a.
There are a few other job descriptions in this field, including Data Architect, BI Architect, and Senior Big Data Engineer, in addition to Big Data Engineer.
There are numerous options:
- Stay in data engineering and advance to the position of senior engineer. Typically, this entails progressing from simple data marts to complicated data pipelines, as well as moving from individual contributions to leading a team of engineers.
- Data engineers are already aware of ETL(Extract, Transform, Load Procedure) and data layers, which are the backbone of any software app or website, thus understanding application development will open up the way to software and web development.
- Data engineers offer the backbone for analytics apps and are familiar with data structures used in BI, Analytics, and Machine Learning, thus learning those applications in addition to analytical abilities and becoming a data consumer is a natural progression.
- Data engineers currently handle the platforms of data applications and would have an understanding of network interconnection, so it’s a natural progression to also manage the platforms of other applications, such as telephony and email.
- Transition to project management – By managing data pipelines, data engineers can gain a better understanding of the moving parts that go into most data projects. This will bring the engineer closer to the business, allowing them to take a more holistic view of what the data engineer, data analyst, application developer, and user/client are doing.
How to Become a Big Data Engineer
Big data engineer positions are in high demand, and big data engineers have considerable technical expertise and years of experience.
A Bachelor’s degree in computer science, software engineering, mathematics, or another related field degree is required to work as a big data engineer. A big data engineer needs a variety of technical skills and expertise in addition to a degree to be successful in their position. So, whether it’s SQL, Python, or a number of cloud platforms, an aspiring big data engineer may succeed with the correct education.
To become a data engineer, you must learn all of the principles involved. Data engineering entails gathering, managing, and processing information.
You should learn the following skills to become a data engineer :
Data Structures And Algorithms
A data structure is a method of organizing data to make it easier to handle. When working with data, you must keep it in a logical order so that you can access it quickly.
Different forms of data structures (sometimes known as databases) exist. You’ll need to familiarise yourself with each of them.
Here are a few examples:
- Array
- Heap
- Binary Tree
- Graph
- Queue
- Matrix
Algorithms are instructions for doing a series of tasks in a specified order. Algorithms are usually independent of the programming language.
This indicates that an algorithm can be used regardless of the programming language.
Algorithms will be used in data structures for the following tasks:
- Locating a record in a database
- Adding a record to a database
- Sorting objects into a specific order
- Deleting an item
- It is a fundamental data engineering idea. As a result, you should devote a significant amount of effort to understanding it.
SQL
SQL is an acronym for Structured Query Language. It has been on the market since the 1970s, and many developers, engineers, and analysts consider it to be their first choice. This is a language that every data engineer should be familiar with. Among data professionals, it is one of the most widely used programming languages. SQL is the most used language for generating database queries from a client programme.
Programming Languages
You must have a strong command of programming languages such as Python and Java. Python may be found almost anywhere. It is an absolute must-have for any data nerd. It’s extremely popular due to its versatility and ease of usage.
Any task you wish to do can be accomplished with the help of a Python library. You should be familiar with both Java and Scala. This is because most data storage solutions, such as Hadoop, HBase, Apache Spark, and Apache Kafka, are developed in these languages. You can’t use these tools unless you know how to use these languages. It will assist you in comprehending how these instruments function and what you can accomplish with them. Each of these languages has its own distinct characteristics. Scala is quick, Java is expansive, and Python is adaptable.
Big Data Tools
Tools for Big Data
In this field, there are some tools that are widely used. They are as follows:
- Apache Hadoop
- Apache Spark
- Apache Kafka
One must discover as much as you can about them. It’s important to learn about these big data tools and technology since they make data storage and administration easier.
Professionals, for example, utilize Hadoop to solve challenges involving large amounts of data and collecting. It’s a collection of open-source software frameworks and solutions.
Similarly, Spark provides a programming interface for clusters.
Many employers look for individuals who are comfortable with these technologies.
Distributed System
Clusters of data exist, each of which functions independently. Due to the existence of more member nodes, a large cluster has a higher likelihood of generating difficulties than a smaller one. You will need to learn about data clusters and their systems in order to become a data engineer. You’ll also need to understand the many types of issues that data clusters face and how to handle them.
Tips for Becoming a Big Data Engineer – Checklist
Here’s a quick rundown of the steps to becoming a data engineer:
- Earning a bachelor’s degree in computer science, or a related field — Earning a bachelor’s degree in computer science, or a related field is a good approach to get acquainted with the field of data engineering. You may even discover a specialist field in which you would like to work as a result of your study.
- Employers in the field are looking for employees with unique abilities and a solid grasp of software and computer languages. Sharpen your big data skills. Practice, personal projects, and continued education will help you improve your skills.
- Get a part-time job, even if it’s in IT, to build experience. You can build on that knowledge by learning about new big data trends and solutions that you weren’t aware of previously.
- As you apply for new roles and grow in your profession, get certifications to help you specialize even more and make you a more competitive candidate.
- Obtain a master’s degree in data engineering. A graduate degree is one technique to differentiate yourself as a job candidate. It demonstrates that you’ve gone above and beyond to expand your expertise.
Skills Required to Become Big Data Engineer

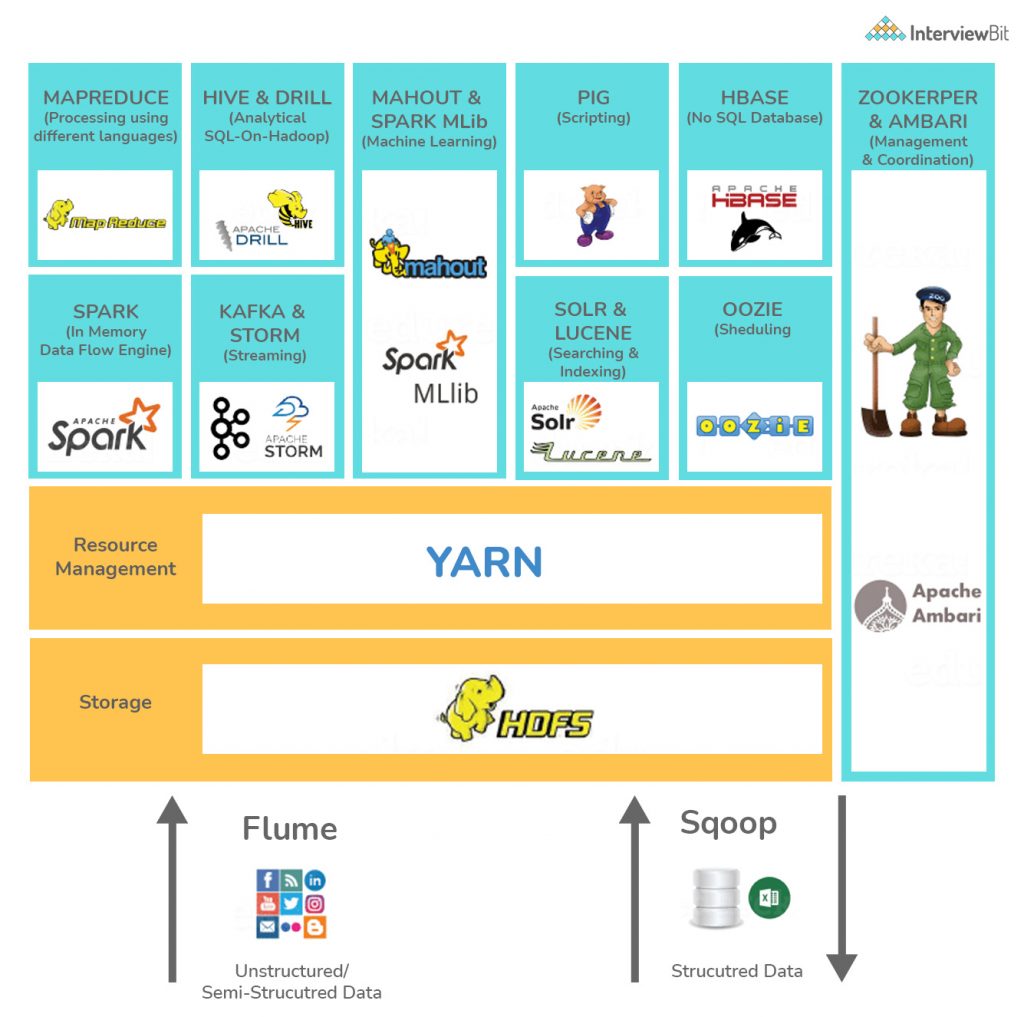
You’ll need specific abilities to work as a Big Data Engineer. Proficiency with Big Data Frameworks/Hadoop-based technologies is essential on the technical side. The Hadoop Ecosystem contains a variety of tools for various applications.
The following are some fundamental tools that you must master:
- HDFS (High-Definition File System) (Hadoop Distributed File System)
- YARN
- MapReduce
- HIVE & PIG
- Sqoop & Flume
- ZooKeeper
- Oozie
Database architecture and design are also important. Data Models and Data Schemas are equally important abilities for a Data Engineer to have.
Some other Skills and qualifications which is expected from a big data engineer are enlisted as follows:
- The principles of distributed computing are well-understood.
- Unless you have specific Big Data DevOps responsibilities for this, management of Hadoop cluster with all included services.
- Unless you have specific Big Data DevOps roles for this, you should be able to fix any ongoing issues with operating the cluster.
- Hadoop v2, MapReduce, and HDFS knowledge
- If stream-processing is relevant to the role, experience designing stream-processing systems utilizing technologies such as Storm or Spark-Streaming is required.
- Knowledge of Big Data querying technologies like Pig, Hive, and Impala is a plus.
- Knowledge of working on Spark.
- Integration of data from a variety of sources is a plus.
- Knowledge of NoSQL databases like HBase, Cassandra, and MongoDB.
- Knowledge of an ETL framework like Flume requires knowledge of numerous ETL methodologies and frameworks.
- Knowledge of different messaging systems, such as Kafka, RabbitMQ, etc.
Knowledge of Big Data machine learning toolkits such as Mahout, SparkML, or H2O - A thorough understanding of Lambda Architecture, including its benefits and limitations.
- Cloudera/MapR/Hortonworks experience

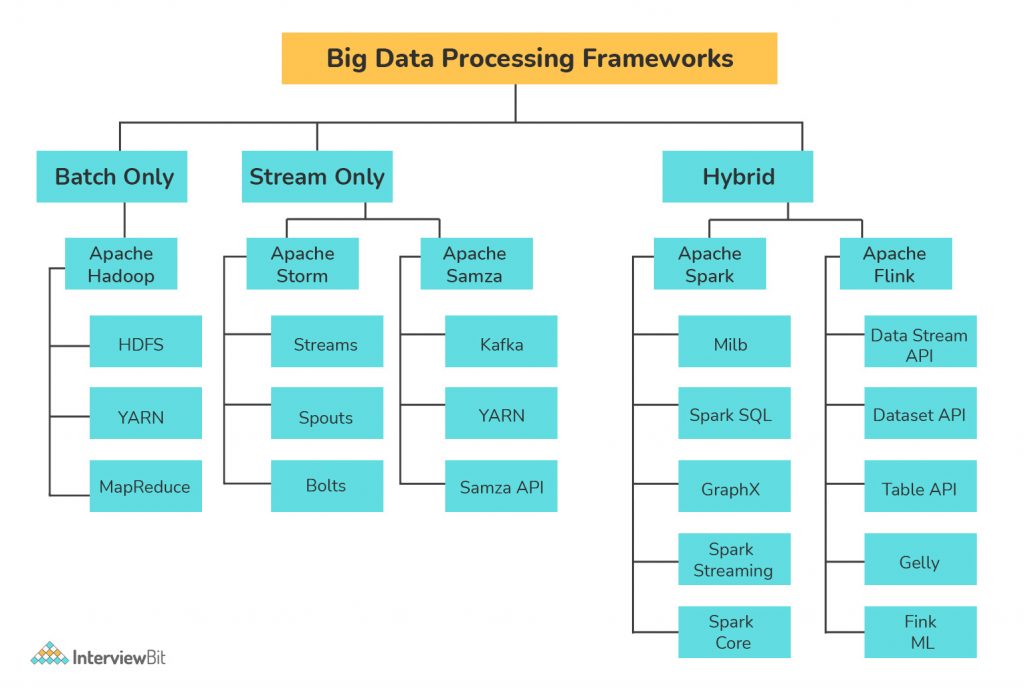
Big Data Engineer Responsibilities

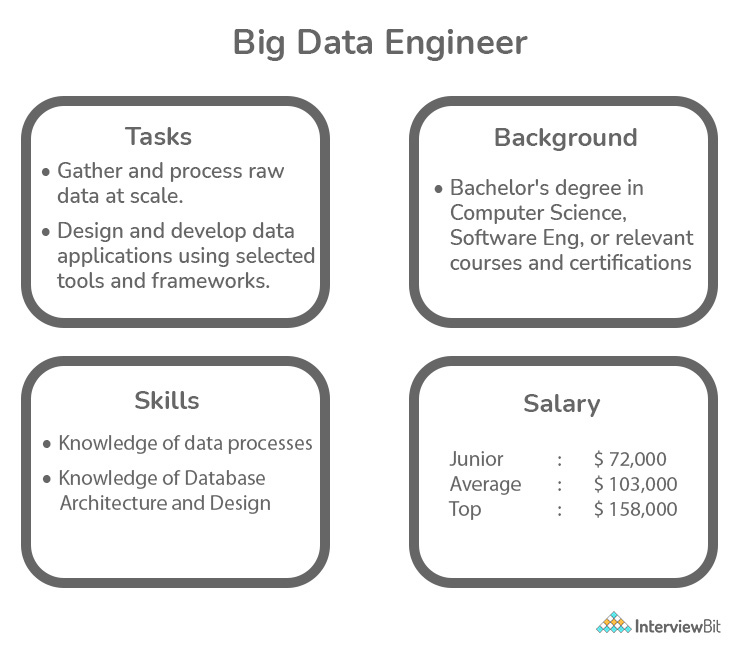
The main functions of a big data engineer are similar to those of a data engineer:
- Designing big data engineer architecture platform
- Maintenance of the data pipeline
- Modifying and administering integration tools, databases, warehouses, and analytical systems
- Data organization and management
However, in terms of working with big data, a big data engineer’s tasks are unique. Let’s have a look at some of them.
Performance Optimization
When it comes to large data platforms, performance is crucial. To speed up query execution, big data engineers must monitor the entire process and make required infrastructure adjustments. This includes the use of the following items.
- Techniques for improving database performance. Data partitioning is one of them, which involves dividing and storing data into independent, self-contained chunks. For quick lookup, each data block is given a partition key
- Database indexing is another strategy for arranging data to speed up data retrieval processes in huge tables. Denormalization is a technique used by big data engineers to reduce the number of tables joins by adding redundant data to one or more tables.
- Data ingestion is quick and easy. When it comes to transporting data in numerous formats that are continually speeding, things get a little more complicated. Big data engineers can capture and inject more data into the data lake by employing data mining techniques and other data ingestion APIs to find patterns in data sets.
Stream Processing
One of the most typical jobs for big data engineers nowadays is to set up and manage streaming flows.
Transactional data, IoT devices, and hardware sensors are all being used extensively by businesses. What makes data streams so unique is their continuous flow of updates that quickly lose their significance. As a result, such data must be processed right away. A standard batch processing strategy will not suffice in this case. Big data engineers feed data streams to event stream processors, which process data in real time, keep it updated, and deliver it to the user on a regular basis.


Deploying ML models
Although developing production-ready code and building it in the pipeline is not a fundamental ability for a big data engineer, they are frequently involved in the deployment process if a data scientist isn’t. We have streaming photos, for example, and we need to classify them in the pipeline before storing them. In this instance, a big data engineer must deploy an ML model in the data pipeline that corresponds to the data.
Following is enlisted other responsibilities that is expected from a Big data engineer:-
- At a large scale, collect and process raw data.
- Create data apps with the help of a few tools and frameworks.
- As needed and requested, read, extract, transform, stage, and load data into selected tools and frameworks.
- Perform scripts, scrape websites, call APIs, and write SQL queries, among other things.
- Integrate your work into our production systems by working closely with the engineering team.
- Transform unstructured data into an analysis-ready format.
- Analyze the data that has been processed.
- As needed, ad hoc analysis can be used to support business choices.
- Data performance is being monitored, and infrastructure is being modified as appropriate.
- Create policies for data retention.
Big Data Engineer Job Description
To comprehend the work of a big data engineer, you must first comprehend that big data is a large collection of data that typical software solutions are unable to handle. Traditional data collecting is more structured, but big data is unstructured. To complete the task, big data engineers employ a variety of technological talents.
Big data engineers are software developers who must be able to code and be an engineer all at the same time. Any big data engineer could find oneself executing a variety of duties on any given day of the week, as this is a multi-faceted position. Identifying, extracting, and distributing data in a usable manner are all tasks that must be completed. Others are then given this information to review. A big data engineer must guarantee that the data they extract is accurate while at work. A big data engineer’s day could include dealing with cloud computing environments, assisting in the documentation of any requirements, resolving data ambiguities, and more.
When to Hire a Big Data Engineer?
If your company is in one of the following industries, you will almost certainly require a big data engineer:
- Internet of Things (IoT): Because they have a lot of devices streaming data all the time, IoT companies need quick data ingestion. A big data engineer will set up the data flow with care, ensuring that no essential data is lost.
- Finance: Financial institutions have particularly unique processing requirements since they deal with a wide range of input data.
- Social: By analyzing user data, social media firms can better understand who their customers are and what they like, allowing them to offer items to them more effectively. Social media companies use cutting-edge technologies or even develop their own big data solutions, such as Facebook’s Presto and Twitter’s Apache Storm.
Marketing and eCommerce organizations capture large amounts of data about their clients by tracking every online contact with their site. Given that this data is scattered among hundreds of web server log files and other systems, big data experts have a lot of work ahead of them.
- Government and non-profit organizations: Big data is used in all areas of government, and it comes in a variety of flavors. Big data engineers will set up data processing where datasets will be brought together so that they may be processed all at once for the most useful insights.
Big Data Engineer Resume
How to structure a resume


In front of an interviewer, your resume is your first impression. It’s the first and most important step toward your objective. You can construct your CV in one of two ways:
- Chronological: This is the classic method of constructing a resume, in which you list your experience in the order in which it occurred. In conservative fields, this sort of resume is preferred.
- Functional: This is a completely new method in which you list your most relevant experience in relation to the skills necessary. Your recruiter won’t have to sift through your entire resume to uncover the necessary abilities. This is a more concentrated and succinct approach of presenting yourself to an interviewer.
While creating your CV, there are a few crucial points to keep in mind.
- The first thing to remember is that your resume should be consistent, simple, and clear in terms of layout and the information it is seeking to express.
- Make sure your résumé is up to date. Building or updating your CV is time-consuming, but the more work you put into it, the better your chances of getting hired. For a single position, a recruiter receives hundreds of resumes, and yours is the one that will get you through the first round.
- A single-page resume should be used for someone with fewer than 8 years of experience. You should only bring a two-page résumé. The resume becomes too long after two pages, and the interviewer loses interest in reading it.
- If you have 2+ years of experience, consider creating a functional resume, in which you simply include relevant experience rather than cramming it with everything. Give the most important to the talents that are essential for the job. It is usually preferable to create a unique CV for each and every job.
- List the activities you participated in, as well as your role in each one. This is where you can demonstrate interpersonal qualities like leadership, teamwork, and so on. Also, make a list of any prizes you’ve received to demonstrate your abilities in various industries.
- Your interests are crucial in breaking the ice with the interviewer. This area also demonstrates that you are a multi-talented individual with a diverse set of abilities and interests.
Tips and guidance on Big Data Engineer Resume
In the case of a Big Data Engineer Resume, the first section should include your professional experience, in addition to your name and contact information.
Work Experience
Always begin with relevant work experience, as this will grab the recruiter’s attention right away. It should be very succinct, crisp, and precise in stating the duties you’ve taken on and the lessons you’ve learned from them.
You can categorize your experience as follows:
- Designation
- The Organization’s Name
- Employment Duration
- In a nutshell, job responsibilities
- Your knowledge or experience gained from that work
Try to mention the software and framework versions.
Using the job description as a guide, you can adjust your experience and specify the tools and abilities that the company requires.
You must realise that there are numerous tools for a single aim, and you will not be able to master them all. Instead of simply stating the tool’s or framework’s name, include a brief explanation of your knowledge and experience with the tool. This will also help the interviewer figure out if you have experience with another tool if you don’t have experience with the exact same tool.
Technical Expertise
Create a Technical skill section after the Job Experience section to list your technical skills. You can list any abilities you believe are necessary for the Big Data Engineer position, as well as any skills you are confident in.
Achievements
After that, Achievements should be the next part. If you discuss too many accomplishments, your interviewer may become distracted and miss the key ones. Mention a few that are relevant and that you are comfortable with.
How to Prepare for Big Data Engineer Interviews
Big data jobs are distinct from traditional IT professions in that they necessitate a greater level of competence in the fields of data analytics and the Hadoop environment. Hands-on experience with big data technologies and concept understanding, in addition to theoretical knowledge, are important for landing these roles. As part of big data interview preparation, it is also necessary to have the relevant training and certifications in the sector. If you want to learn how to crack a big data interview, you must first understand that successful big data interview preparation necessitates a step-by-step approach.
Following are some key steps to follow for an effective big data engineer interview
Machine Learning and Statistics: The field of data science necessitates the use of statistics. The use of statistics to crunch large data sets is very common. As a result, knowing the fundamentals of statistics such as P value, confidence intervals, the null hypothesis, and others is beneficial. R and other statistical tools are widely utilised in decision-making and experimentation.
Furthermore, machine learning is now one of the most important capabilities in the big data ecosystem. Random forests, nearest neighbours, and ensemble methods knowledge can be useful in the interview. These techniques can be implemented in Python, and their use and exposure will help you gain data science competence.
Software Engineering and Basic Programming: It is advantageous to be familiar with basic programming languages as well as statistical programming languages such as R and Python, as well as database languages such as SQL. If you’ve worked with Java or other programming languages before, you’ll have an advantage.
Data Wrangling and Data Visualization: Data visualization tools such as ggplot are extremely beneficial to data scientists. Knowing how to use these tools can aid you in coordinating and comprehending the usage of data in real-world applications. You should be able to clear up data as well. Data Wrangling aids in the detection of corrupt data and the deletion or correction of such data. As a result, understanding data wrangling and data visualization technologies will aid you in preparing for your big data interview.
Familiarity with Data: Companies like Facebook, Amazon, Google, and eBay have massive data collections to analyse. Social media platforms and online shops are in the same boat. As a result, recruiters seek engineers with professional certificates or prior expertise working with data behemoths. Many of the certifications offered by Hortonworks and Cloudera, for example, are well-known in the field. If you are a new employee, having these certifications will be beneficial.
Tips to focus on when attending Big Data Engineer Interview
The next step is to prepare for the big day once you have the necessary skill set and knowledge of big data tools and technologies. Herewith is mentioned some tips to be consider
- Prepare right questions and standard answers
- Practice and follow up
- Get ready with a right CV
- Be ready to face real-time problems scenarios
- Be ready with your questions for the interviewer
Sample Questions that can be asked in Big Data Engineer Interview
- Explain the correlation between Hadoop and Big Data
- Define the terms HDFS and YARN along with their respective components.
- What do you understand about the distributed cache?
- Explain the concept of indexing in HDFS?
- What is your approach to data preparation?
- What do you understand about Edge Nodes in Hadoop?
- What is your understanding of commodity hardware?
- What is Feature Selection?
- Name some outlier detection techniques?
You can check out our Big data Interview Questions track and learn how to crack interviews.
Conclusion
Big Data Engineering is an essential component of every data-driven firm looking to achieve a competitive advantage. Companies might experience project failure if sufficient Data Engineering efforts were not made, resulting in significant financial losses. This article gave you a thorough overview of Big Data Engineering, as well as a list of procedures and abilities that should be included in an ideal Big Data Engineering process.


