

Big Data is a large quantity of data that includes high velocity, high volume, and a wide variety of data. Large amounts of data can be difficult to manage. The Apache Software Foundation developed Hadoop, a framework for processing Big Data, as an attempt to solve this problem.
In this Apache Hive Architecture tutorial, we cover the topic in detail. We first give a brief overview of Apache Hive. Then we see the Hive architecture and its key components. In addition, we see how Apache Hive works in practice.
What is Hive?
The Facebook open-source data warehousing tool Apache Hive was designed to eliminate the job of writing the MapReduce Java program. Facebook developed it to decrease the amount of code it requires.
Hive programs are written in the Hive Query language, which is a declarative language similar to SQL. Hive translates hive queries into MapReduce programs.
Hive queries can be used to replace complicated java MapReduce programs with structured and semi-structured data processing and analyses. A person who is knowledgeable about SQL statements can write the hive queries relatively easily.
The Hive platform makes it simple to perform tasks like:
- Large-scale data analysis
- Perform Ad-hoc queries
- Perform Data encapsulation
Features of Hive:
The key features of Apache Hive are listed below:
- We can use Apache Hive for free. It is open-source.
- Hive can handle large datasets stored in Hadoop Distributed File System using Hive.
- Multiple users can perform queries on the data at the same time.
- The Apache Hive software perfectly matches the low-level interface requirements of Apache Hadoop.
- In order to improve performance, Apache Hive partition and bucket data at the table level.
- Hive provides support for a variety of file formats, including textFile, orc, Avro, sequence file, parquet, Copying, LZO Compression, and so on.
- Hive uses Hive Query Language which is the same as SQL. We don’t need to know any programming languages to work with Hive. We can work with Hive using only basic SQL.
- Hive has a variety of built-in functions.
- The Oracle BI Client Developer’s Kit also provides support for User-Defined Functions for data cleansing and filtering. We can define UDFs according to our requirements.
- External tables are supported by Apache Hive. We can process data without actually storing data in HDFS because of this feature.
- Fast, scalable, and intuitive are the keywords for Hive, which is a fast, extensible tool that uses familiar ideas.
- Hive is a distributed data warehouse tool. Apache Warehouse is a Warehouse software.
- The table structure in Hive is the same as the table structure in a relational database.
- Hive support includes ETLs. Hive is an effective ETL tool.
- Hive can utilise files stored in HDFS and other similar data storage systems such as HBase to access data.
- Hive is used to perform online analytical processing in OLAP (Online Analytical Processing).
- Hive can accommodate client applications written in PHP, Python, Java, C++, and Ruby.
- Hive has an optimizer that applies rules to logical plans to improve performance.
- We can run Ad-hoc queries in Hive, which are loosely typed commands or queries whose values depend on some variable for the data analysis.
- Hive can be used to implement data visualisation in Tez. Hive can be used to integrate with Apache Tez to provide real-time processing capabilities.
Hive Architecture:

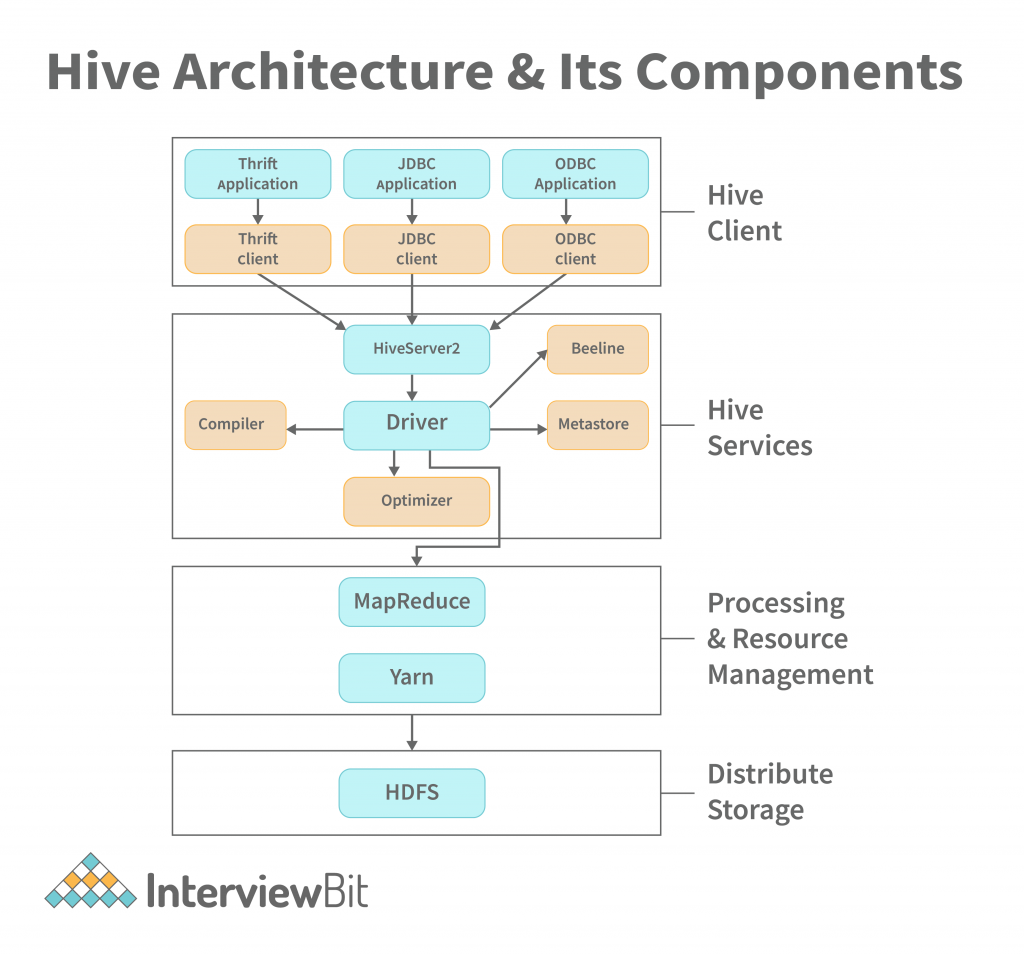
The figure above provides a glimpse of the architecture of Apache Hive and its main sections. Apache Hive is a large and complex software system. It has the following components:
Hive Client:
Hive drivers support applications written in any language like Python, Java, C++, and Ruby, among others, using JDBC, ODBC, and Thrift drivers, to perform queries on the Hive. Therefore, one may design a hive client in any language of their choice.
The three types of Hive clients are referred to as Hive clients:
- Thrift Clients: The Hive server can handle requests from a thrift client by using Apache Thrift.
- JDBC client: A JDBC driver connects to Hive using the Thrift framework. Hive Server communicates with the Java applications using the JDBC driver.
- ODBC client: The Hive ODBC driver is similar to the JDBC driver in that it uses Thrift to connect to Hive. However, the ODBC driver uses the Hive Server to communicate with it instead of the Hive Server.
Hive Services:
Hive provides numerous services, including the Hive server2, Beeline, etc. The services offered by Hive are:
- Beeline: HiveServer2 supports the Beeline, a command shell that which the user can submit commands and queries to. It is a JDBC client that utilises SQLLINE CLI (a pure Java console utility for connecting with relational databases and executing SQL queries). The Beeline is based on JDBC.
- Hive Server 2: HiveServer2 is the successor to HiveServer1. It provides clients with the ability to execute queries against the Hive. Multiple clients may submit queries to Hive and obtain the desired results. Open API clients such as JDBC and ODBC are supported by HiveServer2.
Note: Hive server1, which is also known as a Thrift server, is used to communicate with Hive across platforms. Different client applications can submit requests to Hive and receive the results using this server.
HiveServer2 handled concurrent requests from more than one client, so it was replaced by HiveServer1.
Hive Driver: The Hive driver receives the HiveQL statements submitted by the user through the command shell and creates session handles for the query.
Hive Compiler: Metastore and hive compiler both store metadata in order to support the semantic analysis and type checking performed on the different query blocks and query expressions by the hive compiler. The execution plan generated by the hive compiler is based on the parse results.
The DAG (Directed Acyclic Graph) is a DAG structure created by the compiler. Each step is a map/reduce job on HDFS, an operation on file metadata, and a data manipulation step.
Optimizer: The optimizer splits the execution plan before performing the transformation operations so that efficiency and scalability are improved.
Execution Engine: After the compilation and optimization steps, the execution engine uses Hadoop to execute the prepared execution plan, which is dependent on the compiler’s execution plan.
Metastore: Metastore stores metadata information about tables and partitions, including column and column type information, in order to improve search engine indexing.
The metastore also stores information about the serializer and deserializer as well as HDFS files where data is stored and provides data storage. It is usually a relational database. Hive metadata can be queried and modified through Metastore.
We can either configure the metastore in either of the two modes:
- Remote: A metastore is not enabled in remote mode, and non-Java applications cannot benefit from Thrift services.
- Embedded: A client in embedded mode can directly access the metastore via JDBC.
HCatalog: HCatalog is a Hadoop table and storage management layer that provides users with different data processing tools such as Pig, MapReduce, etc. with simple access to read and write data on the grid.
The data processing tools can access the tabular data of Hive metastore through It is built on the top of Hive metastore and exposes the tabular data to other data processing tools.
WebHCat: The REST API for HCatalog provides an HTTP interface to perform Hive metadata operations. WebHCat is a service provided by the user to run Hadoop MapReduce (or YARN), Pig, and Hive jobs.
Processing and Resource Management:
Hive uses a MapReduce framework as a default engine for performing the queries, because of that fact.
MapReduce frameworks are used to write large-scale applications that process a huge quantity of data in parallel on large clusters of commodity hardware. MapReduce tasks can split data into chunks, which are processed by map-reduce jobs.
Distributed Storage:
Hive is based on Hadoop, which means that it uses the Hadoop Distributed File System for distributed storage.
Working with Hive:
We will now look at how to use Apache Hive to process data.

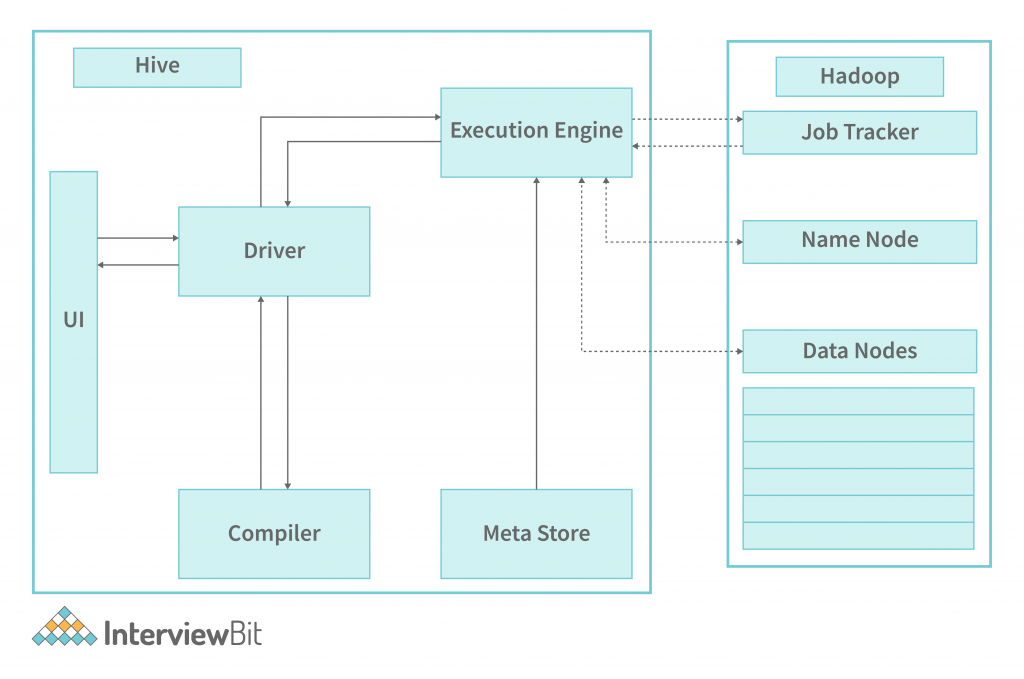
- The driver calls the user interface’s execute function to perform a query.
- The driver answers the query, creates a session handle for the query, and passes it to the compiler for generating the execution plan.
- The compiler responses to the metadata request are sent to the metaStore.
- The compiler computes the metadata using the meta data sent by the metastore. The metadata that the compiler uses for type-checking and semantic analysis on the expressions in the query tree is what is written in the preceding bullet. The compiler generates the execution plan (Directed acyclic Graph) for Map Reduce jobs, which includes map operator trees (operators used by mappers and reducers) as well as reduce operator trees (operators used by reducers).
- The compiler then transmits the generated execution plan to the driver.
- After the compiler provides the execution plan to the driver, the driver passes the implemented plan to the execution engine for execution.
- The execution engine then passes these stages of DAG to suitable components. The deserializer for each table or intermediate output uses the associated table or intermediate output deserializer to read the rows from HDFS files. These are then passed through the operator tree. The HDFS temporary file is then serialised using the serializer before being written to the HDFS file system. These HDFS files are then used to provide data to the subsequent MapReduce stages of the plan. After the final temporary file is moved to the table’s location, the final temporary file is moved to the table’s final location.
- The driver stores the contents of the temporary files in HDFS as part of a fetch call from the driver to the Hive interface. The Hive interface sends the results to the driver.
Different Modes of Hive:
A hive can operate in two modes based on the number of data nodes in Hadoop.
- Local mode
- Map-reduce mode
When using Local mode:
- We can run Hive in pseudo mode if Hadoop is installed under pseudo mode with one data node.
- In this mode, we can have a data size of up to one machine as long as it is smaller in terms of physical size.
- Smaller data sets will be processed rapidly on local machines due to the processing speed of small data sets.
When using Map Reduce mode:
- In this type of setup, there are multiple data nodes, and data is distributed across different nodes. We use Hive in this scenario
- It will be able to handle large amounts of data as well as parallel queries in order to execute them in a timely fashion.
- By turning on this mode, you can increase the performance of data processing by processing large data sets with better performance.
Conclusion
The Hive Architecture tutorial is simple in nature, as it compares Apache Hive with a data warehouse. The most important part of Apache Hive is the Hive clients, Hive services, Processing framework, and Resource Management framework and storage. Apache Hive is an open-source data warehouse tool.
The user sends Hive queries to the Hive through the user interface. The compiler generates the Execution Plan. The Execution Engine performs the function.


