



 Join WhatsApp Group
Join WhatsApp Group

Problem Statement
Design and implement a data structure for LRU (Least Recently Used) cache. It should support the following operations: get and set.
- get(key) – Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.
- set(key, value) – Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least recently used item before inserting the new item.
The LRU Cache will be initialized with an integer corresponding to its capacity. Capacity indicates the maximum number of unique keys it can hold at a time.
Definition of “least recently used” : An access to an item is defined as a get or a set operation of the item. “Least recently used” item is the one with the oldest access time.
Examples:
Confused about your next job?
Input: [“LRUCache”, “set”, “set”, “get”, “set”, “get”, “set”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
Output: [null, null, null, 1, null, -1, null, -1, 3, 4]
Explanation:
lRUCache.set(1, 1); // cache is {1=1}
lRUCache.set(2, 2); // cache is {1=1, 2=2}
lRUCache.get(1); // return 1
lRUCache.set(3, 3); // LRU key was 2, evicts key 2, cache is {1=1, 3=3}
lRUCache.get(2); // returns -1 (not found)
lRUCache.set(4, 4); // LRU key was 1, evicts key 1, cache is {4=4, 3=3}
lRUCache.set(1); // return -1 (not found)
lRUCache.set(3); // return 3
lRUCache.set(4); // return 4
Approach
Before directly jumping into the algorithm, let us first analyse the properties of LRU Cache.
- Ordered: The input has to be ordered to distinguish the recently used and longest unused.
- Fast Search: Able to identify if a key exists in the cache.
- Fast Deletion: If the cache is full, delete the last element.
- Fast Insertion: Insert the data to the head upon each visit.
From the above, it can be concluded that a hashmap can be used for searching since searching in a hashmap is O(1). But in hashmap data is unordered, hence it would take O(N) time for deletion and insertion.Another data structure we can think of is a linked list. In the linked list, the data is ordered. Hence, deletion and insertion can be done in O(1) or constant time, but searching in a linked list takes linear time.
So, the idea is to come up with a new data structure combining both the ideas above i.e. hashed linked list.
The data structure hashed linked list consists of a hash map and a doubly linked list. This ensures that all the operations can be performed in O(1).
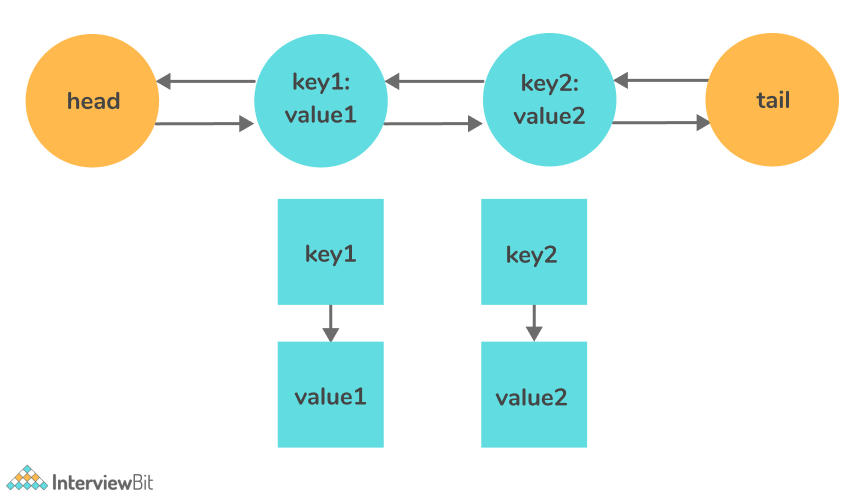
The question remains, why do we need a doubly-linked list and not a single linked list?
The answer is, whenever we need to delete a node from the linked list, it can be easily done by updating the pointer of the nodes present before and after the given nodes. So, deletion can be performed in constant time.
Algorithm:
- For the set function, update the value of the given node in the hashed linked list and insert it at the front of the list. If a node with the given value already exists, delete that node and update the pointers.
- In case, the capacity of the cache is full, delete the last node of the linked list.
- For the get function, it can be obtained by printing the hash value corresponding to the key.
C++ Implementation
class Node {
public:
int key, value;
Node *prev, *next;
Node(int k, int v): key(k), value(v), prev(NULL), next(NULL) {}
};
class DoublyLinkedList {
Node *front, *rear;
bool isEmpty() {
return rear == NULL;
}
public:
DoublyLinkedList(): front(NULL), rear(NULL) {}
Node* add_page_to_head(int key, int value) {
Node *page = new Node(key, value);
if(!front && !rear) {
front = rear = page;
}
else {
page->next = front;
front->prev = page;
front = page;
}
return page;
}
void move_page_to_head(Node *page) {
if(page==front) {
return;
}
if(page == rear) {
rear = rear->prev;
rear->next = NULL;
}
else {
page->prev->next = page->next;
page->next->prev = page->prev;
}
page->next = front;
page->prev = NULL;
front->prev = page;
front = page;
}
void remove_rear_page() {
if(isEmpty()) {
return;
}
if(front == rear) {
delete rear;
front = rear = NULL;
}
else {
Node *temp = rear;
rear = rear->prev;
rear->next = NULL;
delete temp;
}
}
Node* get_rear_page() {
return rear;
}
};
class LRUCache{
int capacity, size;
DoublyLinkedList *pageList;
map<int, Node*> pageMap;
public:
LRUCache(int capacity) {
this->capacity = capacity;
size = 0;
pageList = new DoublyLinkedList();
pageMap = map<int, Node*>();
}
int get(int key) {
if(pageMap.find(key)==pageMap.end()) {
return -1;
}
int val = pageMap[key]->value;
// move the page to front
pageList->move_page_to_head(pageMap[key]);
return val;
}
void put(int key, int value) {
if(pageMap.find(key)!=pageMap.end()) {
// if key already present, update value and move page to head
pageMap[key]->value = value;
pageList->move_page_to_head(pageMap[key]);
return;
}
if(size == capacity) {
// remove rear page
int k = pageList->get_rear_page()->key;
pageMap.erase(k);
pageList->remove_rear_page();
size--;
}
// add new page to head to Queue
Node *page = pageList->add_page_to_head(key, value);
size++;
pageMap[key] = page;
}
~LRUCache() {
map<int, Node*>::iterator i1;
for(i1=pageMap.begin();i1!=pageMap.end();i1++) {
delete i1->second;
}
delete pageList;
}
};JavaImplementation
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
}
private void addNode(DLinkedNode node) {
/**
* Always add the new node right after head.
*/
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node){
/**
* Remove an existing node from the linked list.
*/
DLinkedNode prev = node.prev;
DLinkedNode next = node.next;
prev.next = next;
next.prev = prev;
}
private void moveToHead(DLinkedNode node){
/**
* Move certain node in between to the head.
*/
removeNode(node);
addNode(node);
}
private DLinkedNode popTail() {
/**
* Pop the current tail.
*/
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
private Map<Integer, DLinkedNode> cache = new HashMap<>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
head = new DLinkedNode();
// head.prev = null;
tail = new DLinkedNode();
// tail.next = null;
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) return -1;
// move the accessed node to the head;
moveToHead(node);
return node.value;
}
public void set(int key, int value) {
DLinkedNode node = cache.get(key);
if(node == null) {
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
cache.put(key, newNode);
addNode(newNode);
++size;
if(size > capacity) {
// pop the tail
DLinkedNode tail = popTail();
cache.remove(tail.key);
--size;
}
} else {
// update the value.
node.value = value;
moveToHead(node);
}
}
}PythonImplementation
class DLinkedNode():
def __init__(self):
self.key = 0
self.value = 0
self.prev = None
self.next = None
class LRUCache():
def _add_node(self, node):
"""
Always add the new node right after head.
"""
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
def _remove_node(self, node):
"""
Remove an existing node from the linked list.
"""
prev = node.prev
new = node.next
prev.next = new
new.prev = prev
def _move_to_head(self, node):
"""
Move certain node in between to the head.
"""
self._remove_node(node)
self._add_node(node)
def _pop_tail(self):
"""
Pop the current tail.
"""
res = self.tail.prev
self._remove_node(res)
return res
def __init__(self, capacity):
"""
:type capacity: int
"""
self.cache = {}
self.size = 0
self.capacity = capacity
self.head, self.tail = DLinkedNode(), DLinkedNode()
self.head.next = self.tail
self.tail.prev = self.head
def get(self, key):
"""
:type key: int
:rtype: int
"""
node = self.cache.get(key, None)
if not node:
return -1
# move the accessed node to the head;
self._move_to_head(node)
return node.value
def set(self, key, value):
"""
:type key: int
:type value: int
:rtype: void
"""
node = self.cache.get(key)
if not node:
newNode = DLinkedNode()
newNode.key = key
newNode.value = value
self.cache[key] = newNode
self._add_node(newNode)
self.size += 1
if self.size > self.capacity:
# pop the tail
tail = self._pop_tail()
del self.cache[tail.key]
self.size -= 1
else:
# update the value.
node.value = value
self._move_to_head(node)Time Complexity: O(1) for all operations
Space Complexity: O(N), as extra space, is used.
Practice Questions:
Frequently Asked Questions
What is a doubly linked list used instead of a single linked list for LRU Cache?
Since we need to perform the set and get functions in O(1) time, a doubly linked list ensures the deletion of a node in O(1) by adjusting its front and rear pointers.
Is there some other approach to solve the LRU cache?
Yes, there can be several approaches for the problem, but using a hashed linked list is the most suitable data structure since it ensures all the operations in O(1).

