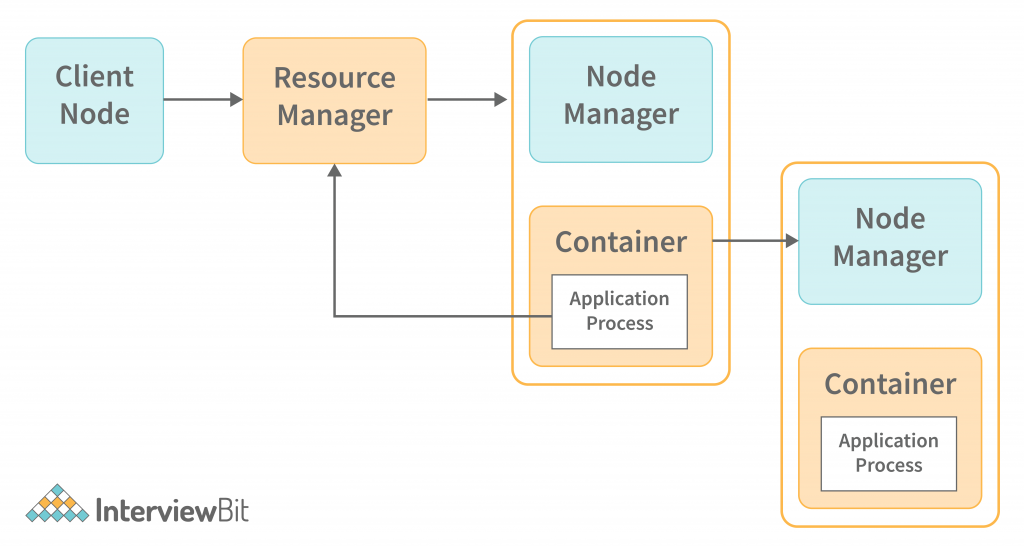
The architecture of YARN is shown in the following diagram. The architecture consists of multiple components such as Resource Management, Node Management, Containers, and Application Master. These components work together to implement the YARN architecture. At the core of YARN, you will find the Resource Manager and Node Manager. These two components are responsible for scheduling and managing Hadoop jobs on the cluster. The Node Manager is responsible for allocating tasks to data nodes in the cluster. The Node Manager will decide which nodes will run the tasks, based on the hardware specifications of each node. The Node Manager will receive task requests from the Resource Manager. The Node Manager will then distribute the tasks to the nodes across the cluster.
In this Apache Hadoop Yarn tutorial, we’ll go over the Yarn architecture and nodes, as well as how to set up a Yarn cluster. You’ll learn about Yarn’s capabilities, its characteristics, and its high-availability modes in this tutorial.
What is YARN Architecture?
YARN can be thought of as analogous to an operating system for a cluster. A cluster is a set of loosely or tightly connected computers that work together to be viewed as a single system. The cluster represents the collection of resources, such as compute, memory, disk-space, and network bandwidth, that YARN must arbitrate among jobs that run on the cluster. Similar to how an operating system presides over the machine’s resources and distributes them among competing processes, YARN allocates cluster resources among competing jobs.
Hadoop YARN Architecture and Component
YARN stands for Yet Another Resource Negotiator. It has two major responsibilities:
- Management of cluster resources such as compute, network, and memory
- Scheduling and monitoring of jobs
YARN achieves these goals through two long-running daemons:
- Resource Manager
- Node Manager
The two components work in a master-slave relationship, where the Resource Manager(RM) is the master and the Node Managers the slave. A single Resource Manager runs in the cluster with one Node Manager per machine. Together, these two components make up the data-computation framework. Let’s discuss the resource manager first.

Resource Manager
The Resource Manager is described in the official documentation as the ultimate authority that arbitrates resources among all the applications in the system. The resource manager consists of two parts:
- Applications Manager: is responsible for accepting job submissions and starting a container for an entity called the ApplicationMaster. It also restarts the ApplicationMaster container if the container fails. We’ll discuss the details around the ApplicationMaster shortly.
- Scheduler: The scheduler is responsible for allocating resources such as disk, CPU, and network running applications, subject to restrictions imposed by queues and capacity. The scheduler does not monitor the applications nor does it initiate restarts on application or hardware failures.
In Unix, a container is a process and in Linux a cgroup. Map and reduce tasks run inside a container. A single machine in the cluster can have multiple containers.
The astute reader would realize that the Resource Manager acts as a single point of failure. If the machine hosting the RM goes down, no jobs can get scheduled. To mitigate this shortcoming, high availability for YARN was introduced in Hadoop 2.4. A pair of Resource Managers runs in Active/Standby configuration to achieve high availability. If the active Resource Manager dies, then the standby one becomes the active and the cluster continues to function correctly. The transition from standby to active mode can be done manually by an administrator or automatically. For automatic transition, Zookeeper is required for election.
Node Manager
The NodeManager is an agent that runs on every machine in the cluster. It is responsible for launching containers on that machine and managing the use of resources by the containers. It reports the usage back to the Scheduler component of the Resource Manager.
Containers
A single node houses a set of CPU, RAM, and other CPU-hungry resources like containers. The life cycle of YARN containers is managed by container launch contexts and resources are made available to applications for certain purposes on a given host.
Application Master
It maintains a registry of running applications and monitors their execution. Whenever a job is submitted to the framework, an Application Master is elected for it. It is in charge of allocating resources from the Resource Manager to the Node Manager, which then monitors and executes the tasks.
YARN Architecture Features
YARN has become popular for the following reasons –
- With the scalability of the resource manager of the YARN architecture, Hadoop may manage thousands of nodes and clusters.
- YARN compatibility with Hadoop 1.0 is maintained by not affecting map-reduce applications.
- Dynamic utilization of clusters in Hadoop is facilitated by YARN, which gives better cluster utilization.
- Multi-tenancy enables an organization to gain the benefits of multiple engines at once.
Application Workflow in Hadoop YARN
The first step of running a YARN application involves requesting the RM (resource manager) to create an Application Master(AM) process. A client submits a job and the RM finds a Node Manager that can launch a container to host the AM process. The AM process represents the client job/application. It can either run the job itself and return or request for additional resources from the RM. In the latter, the RM has Node Managers on other machines launch containers on behalf of the AM process to run the distributed computation. Nodes chosen for new container allocations allow the computation to execute as close as possible to the input data, also known as data locality. Ideally, the container is allocated to a node hosting a replica of the data block. The next preference is a node in the same rack as the input data block, and lastly any available node in the cluster.
YARN applications run from a few seconds to several days. The jobs to applications mapping can happen in three ways:
- One job per application: This is the simplest model.
- Several jobs per application: This is suitable for running several jobs (maybe related) as a workflow or in a single user session. The benefit is that containers can be reused within jobs and intermediate data between jobs can be cached in memory.
- Perpetually running application: In this model, an application that acts as a coordinator keeps running, even forever and is shared amongst various users. Apache Slider and Impala are two applications that employ this strategy. In the case of Apache Slider, a long-running application master launches other applications on the cluster. An always-on application master reduces the latency to execute a job because the overhead of starting an application master is eliminated.
Conclusion
YARN is designed to be a highly scalable, distributed system with fault-tolerant and load-balanced components. YARN is an ideal choice for running distributed applications where a large number of tasks need to be executed in parallel. YARN helps in scaling your application up by introducing a concept called resource allocation. It allows you to allocate resources to your tasks depending on their importance. YARN also provides real-time metrics, monitoring, and alerting. It helps in real-time monitoring of your application and alerts you if there is any task failure.